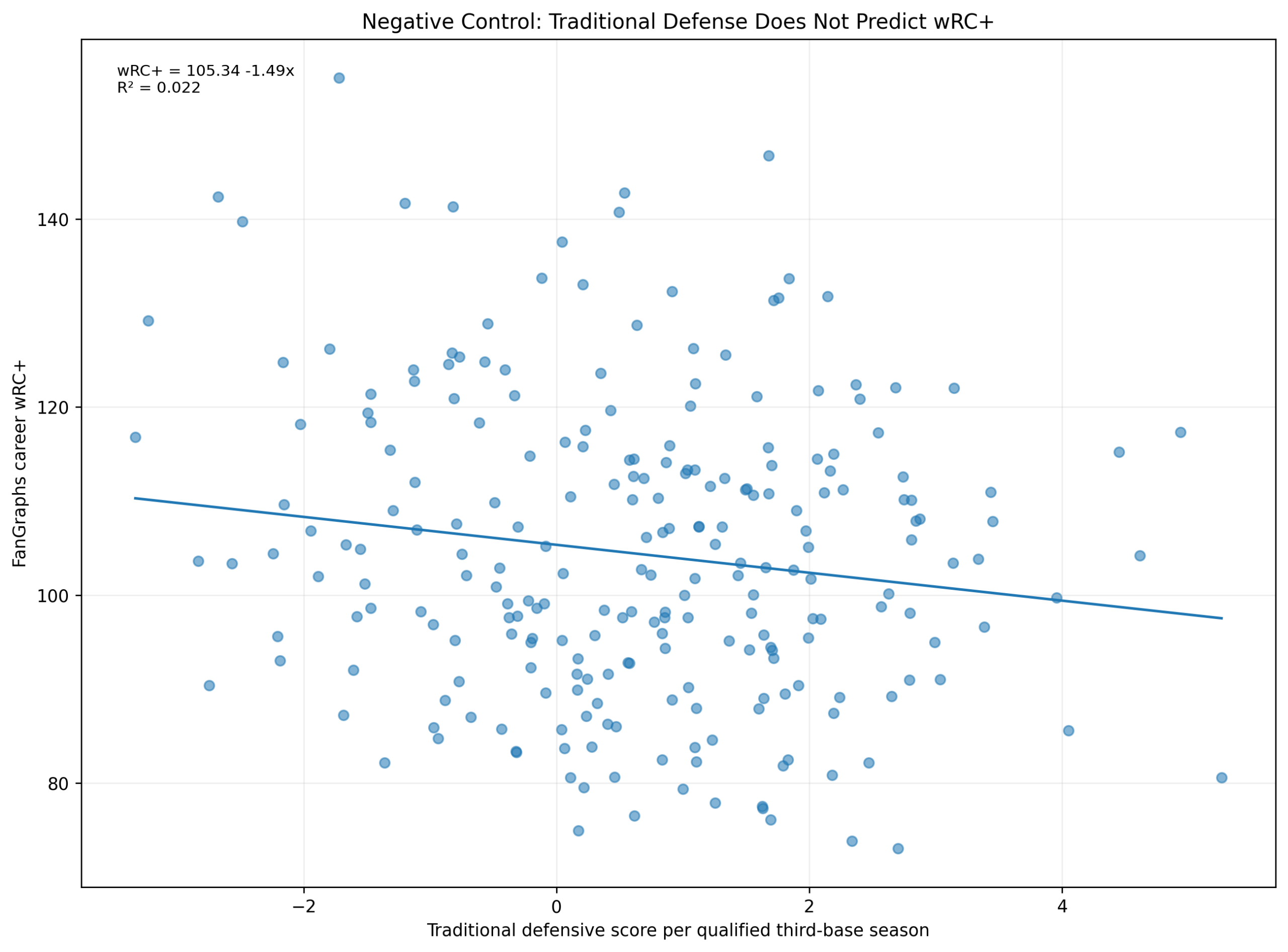
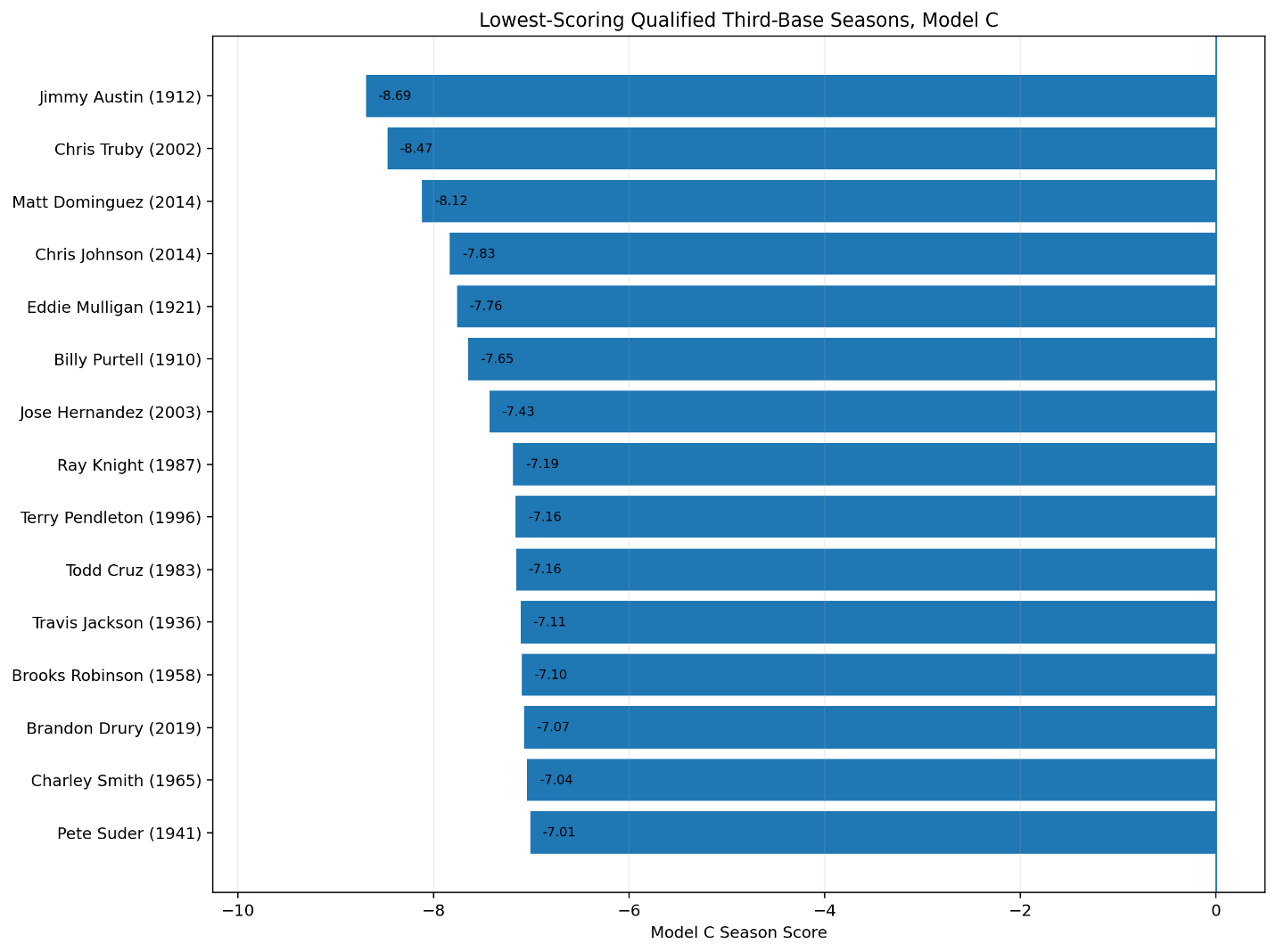
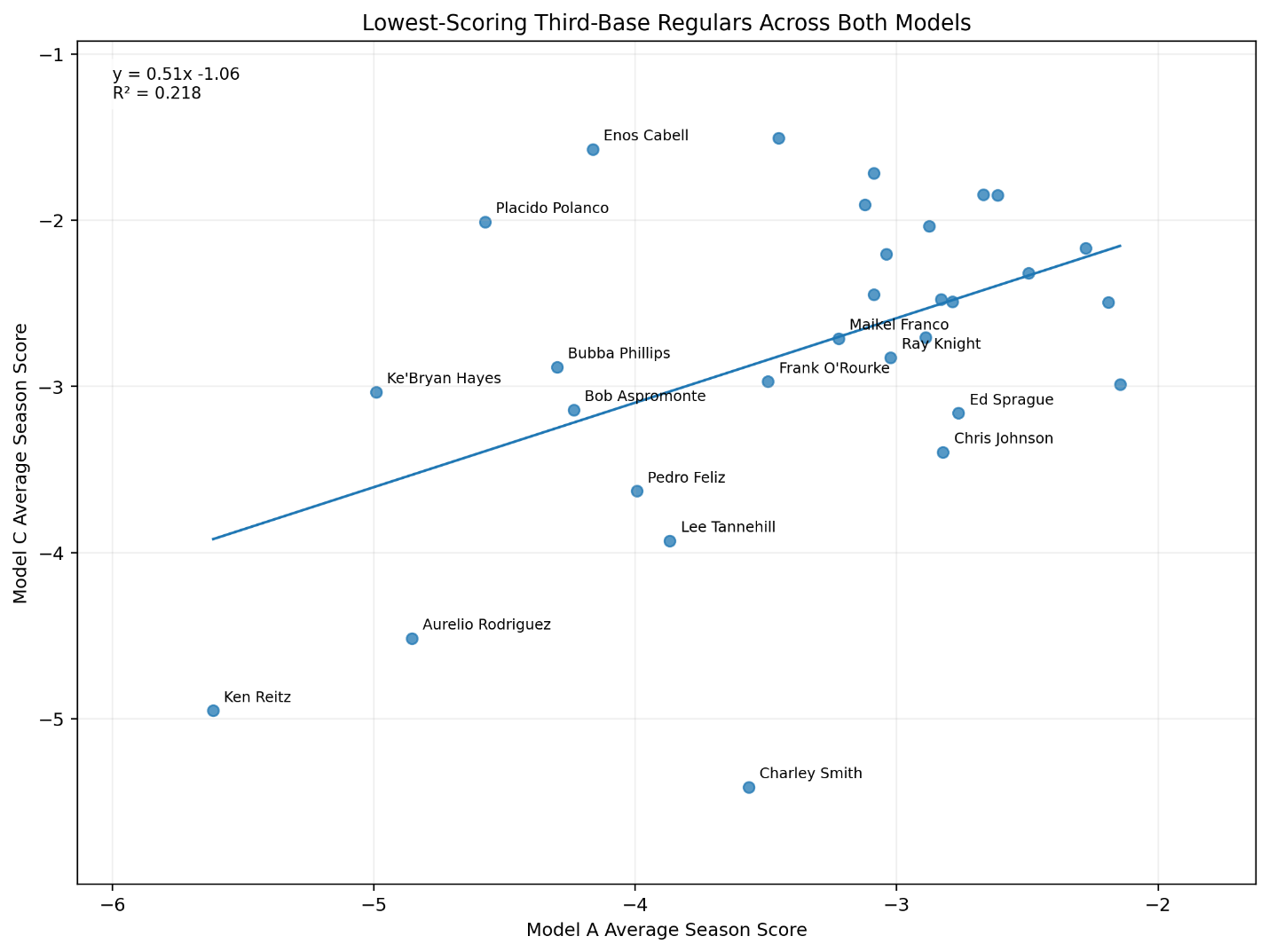
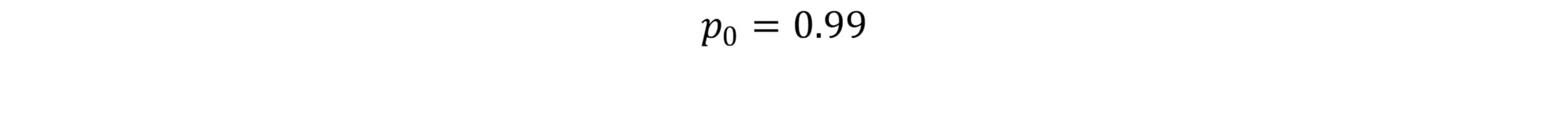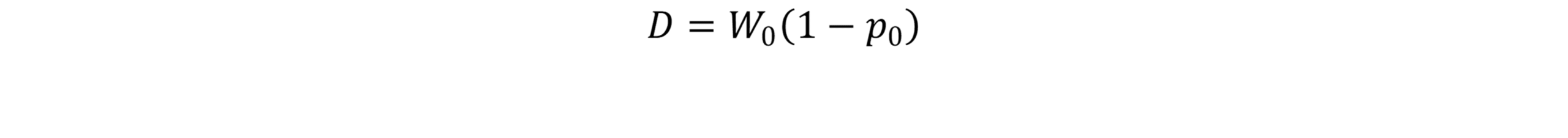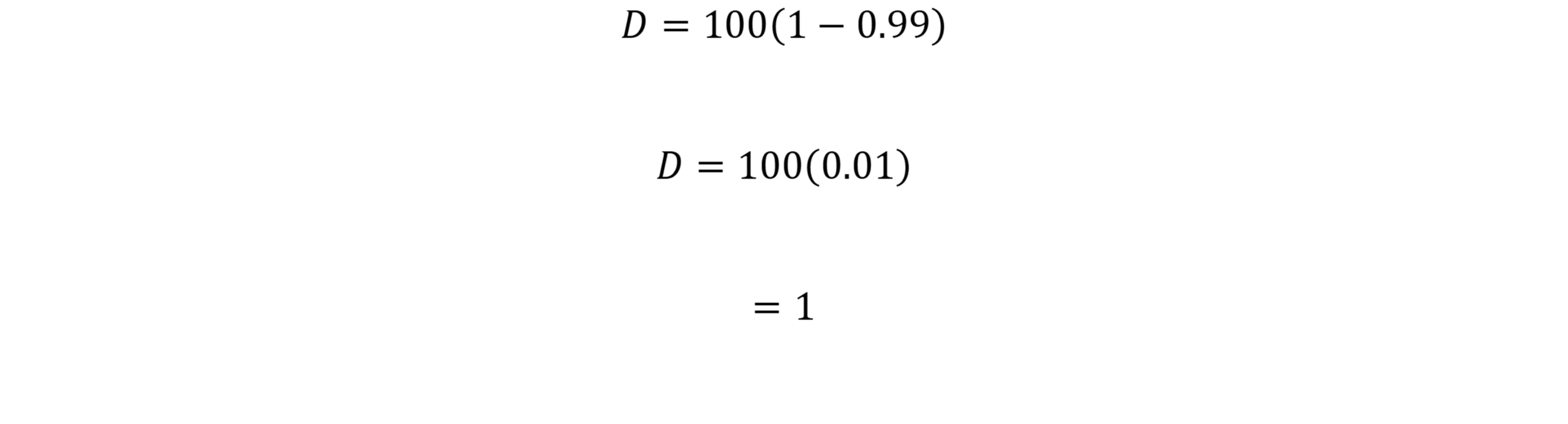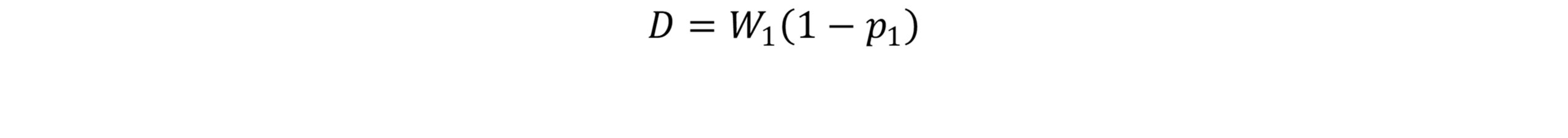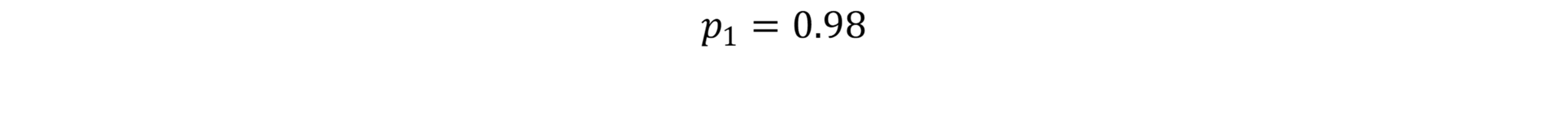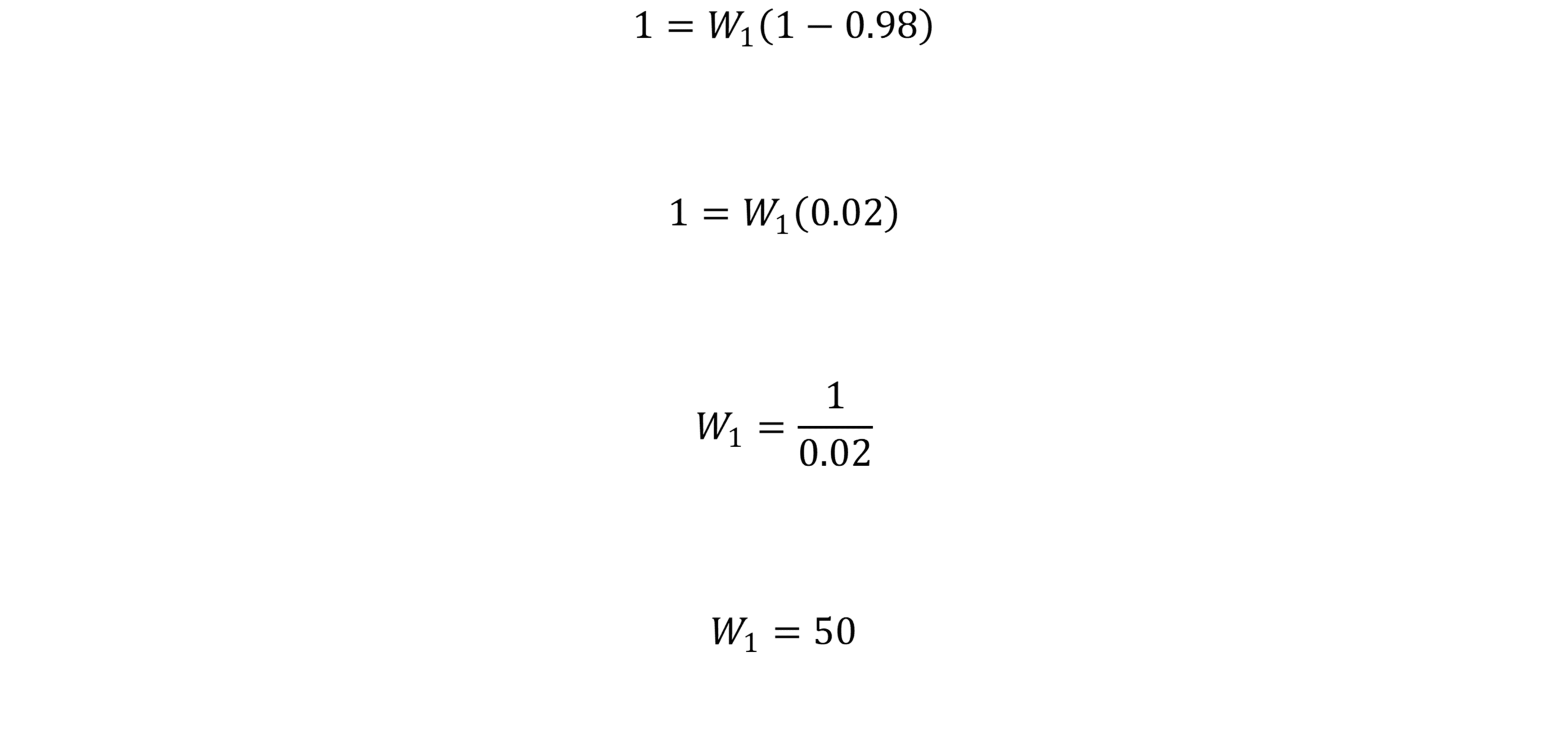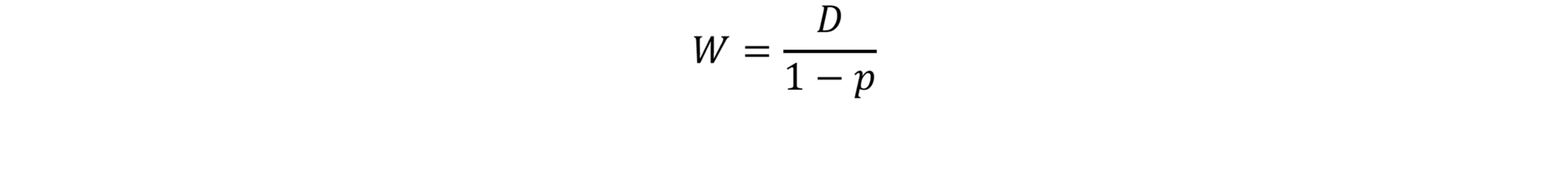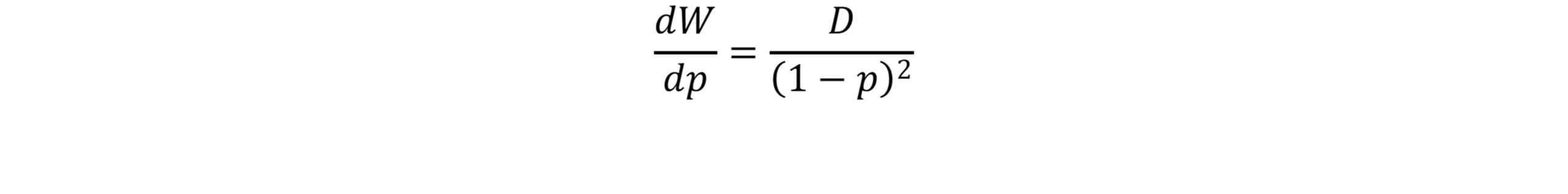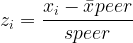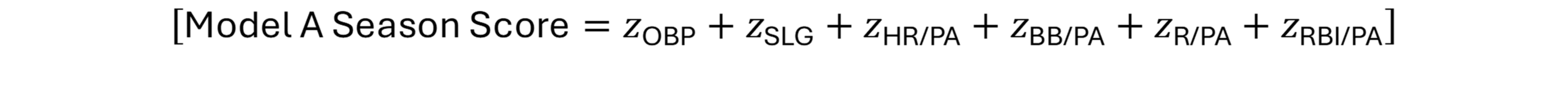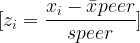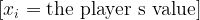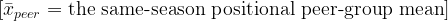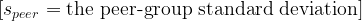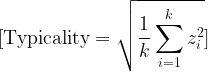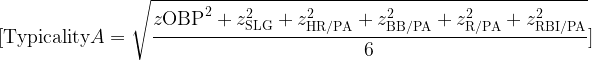At first glance, Zeno’s paradox seems ridiculous.
Of course, Achilles catches the tortoise. Of course, an arrow moves through the air. Of course, I can walk across a room. Well, duh!
We know these things before anyone begins arguing. Motion is one of the most ordinary facts of experience. Every thrown ball, every running child, every falling leaf, every car moving down a road seems to refute Zeno before he even begins.
And yet the paradox remains.
That is what makes Zeno interesting. His argument does not stand because it leads us to believe that motion is impossible. It survives because it reveals something strange about the way we explain motion. Zeno takes an everyday event and slows it down until the ordinary becomes puzzling. He asks us to look not at the fact that something moves, but at what must be true for motion to be intelligible.
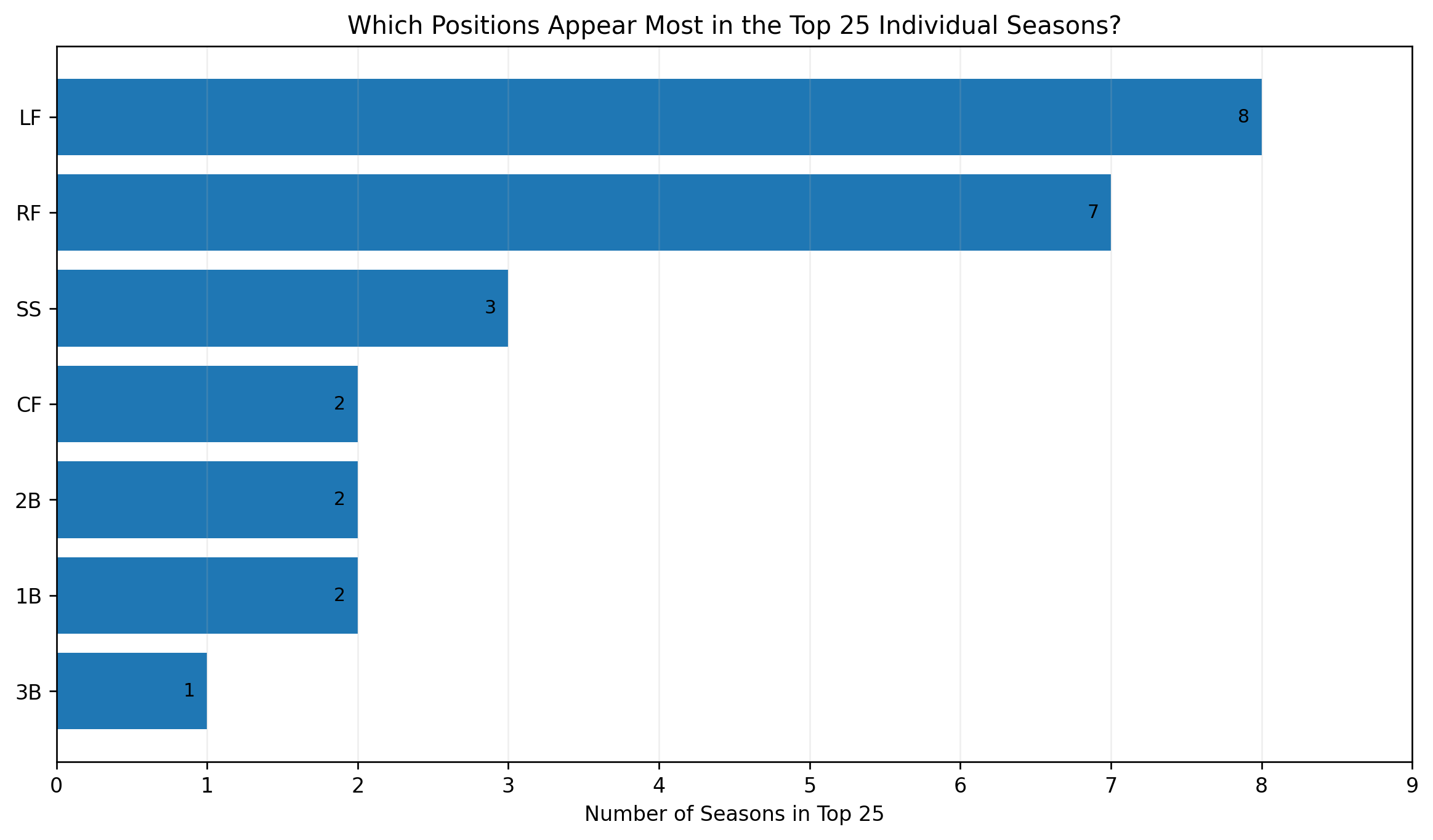
Before I can cross a room, I must first cross half the room. Before I can cross the remaining distance, I must cross half of that. Then half again. Then half again. The distances become smaller and smaller, but the number of required divisions seems to grow without end.
The paradox begins with a simple observation: A finite distance can be divided into infinitely many parts.
That is the unsettling idea at the heart of Zeno’s paradox. The problem is not that the room is too large. The problem is that even a small room appears to contain an infinite structure.
The question becomes: how can a person complete an infinite number of tasks in a finite amount of time?
The Dichotomy Paradox
One of Zeno’s most famous arguments is often called The Dichotomy Paradox. The word “dichotomy” means a division into two parts. In this paradox, every journey must be divided in half.
Suppose I want to walk from one side of a room to the other. To reach the far wall, I first need to reach the halfway point. Once I reach the halfway point, I still need to reach the halfway point of the remaining distance. Then I need to reach the next halfway point. And so on.
The sequence looks like this:
\frac{1}{2},\ \frac{1}{4},\ \frac{1}{8},\ \frac{1}{16},\ \frac{1}{32},\ldotsEach distance is smaller than the one before it. But there is no final term. No matter how many halfway points I cross, another halfway point remains.
That is the apparent trap. If every motion requires completing infinitely many sub-motions, then motion seems impossible. Before I can finish the journey, I must finish an infinite sequence of smaller journeys.
Yet I do finish the journey.
That tension is the paradox.
Figure 1. Divided Finite Distance.
Mathematically, the total distance can be written as an infinite series:
\frac{1}{2}+\frac{1}{4}+\frac{1}{8}+\frac{1}{16}+\cdotsAt first, this looks like an endless accumulation. But modern mathematics gives us a clear answer:
\frac{1}{2}+\frac{1}{4}+\frac{1}{8}+\frac{1}{16}+\cdots = 1More formally:
\sum_{n=1}^{\infty}\left(\frac{1}{2}\right)^n = 1The infinite series has a finite sum.
This is the key mathematical insight. An infinite number of terms does not necessarily mean an infinite total. The terms can shrink quickly enough that their sum approaches a finite limit.
That is why the walker reaches the wall. The distances get smaller, and the times required to cross them also get smaller. The infinite sequence does not require infinite time.
Still, this answer should not make us dismiss Zeno too quickly. The modern solution is powerful, but it also shows why the paradox mattered in the first place. Zeno forced later thinkers to clarify the relationship between infinity, space, time, and motion.
He did not merely ask a trick question. He discovered a pressure point.
Achilles and the Tortoise
The most famous version of Zeno’s argument is Achilles and the tortoise.
Imagine Achilles, the great runner, racing against a tortoise. Since Achilles is much faster, the tortoise receives a head start. Once the race begins, Achilles quickly reaches the place where the tortoise started. But by that time, the tortoise has moved a little farther ahead.
Achilles then reaches that new position. But again, the tortoise has moved forward.
Achilles reaches the next position. The tortoise has moved again.
This continues indefinitely.
The distances shrink. The tortoise’s lead becomes smaller and smaller. But in Zeno’s framing, Achilles must first reach every previous position occupied by the tortoise. Since there are infinitely many such positions, it seems Achilles can never catch up.
Again, common sense rebels.
Of course Achilles catches the tortoise.
But Zeno is not really betting on the tortoise. He is asking whether motion can be explained if every interval contains infinitely many smaller intervals.
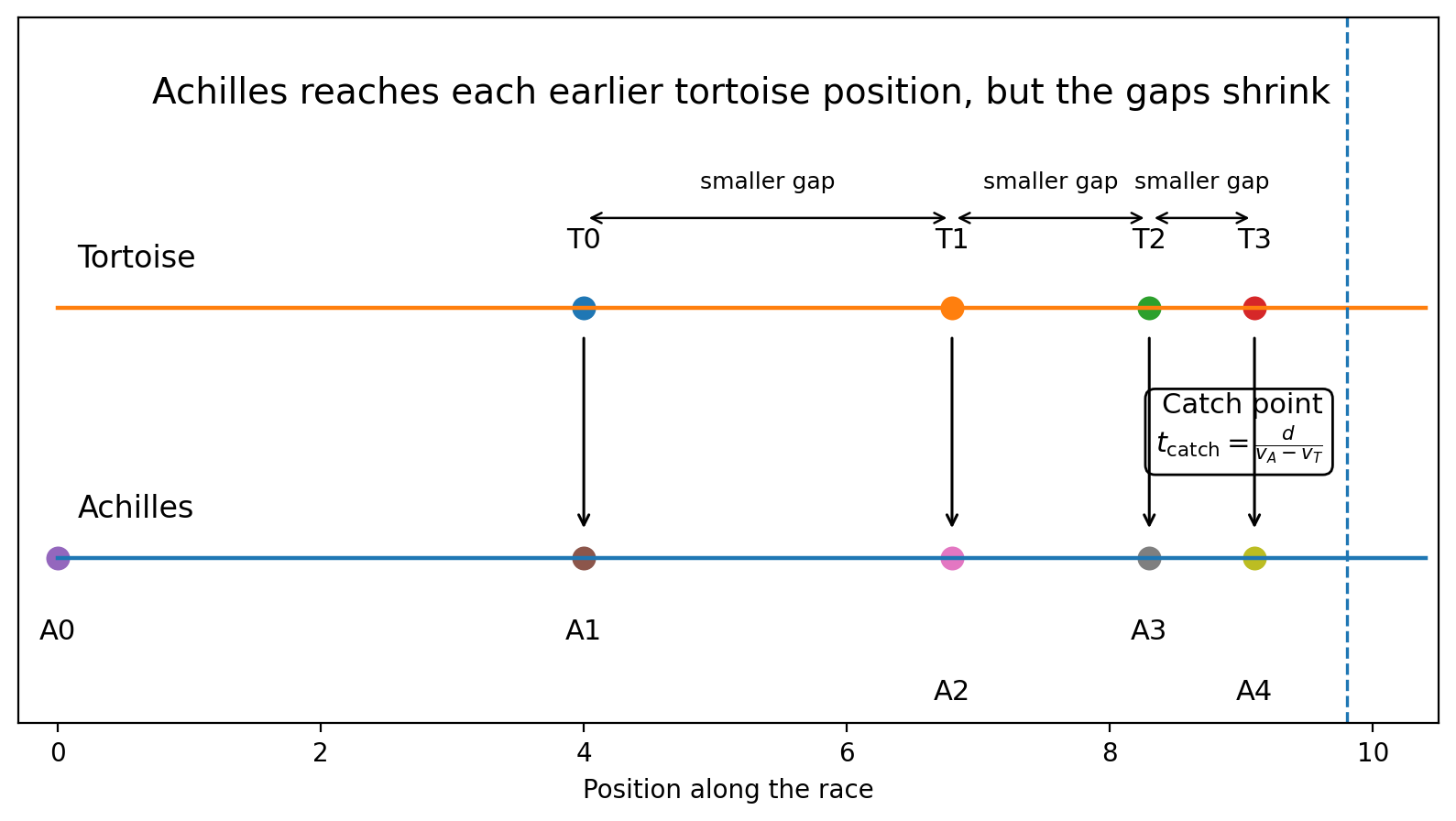
Figure 2. Race Diagram.
Let the tortoise begin with a head start of distance (d). Let Achilles run at velocity (vA), and let the tortoise move at velocity (vT). If Achilles is faster, then:
v_A > v_TThe time it takes Achilles to catch the tortoise is:
t_{\text{catch}} = \frac{d}{v_A - v_T}This equation gives a finite answer. Achilles catches the tortoise when the initial head start has been eliminated by the difference between their speeds.
For example, suppose the tortoise starts 10 meters ahead. Achilles runs at 10 meters per second. The tortoise moves at 1 meter per second. Then:
t_{\text{catch}} = \frac{10}{10 - 1} t_{\text{catch}} = \frac{10}{9}So Achilles catches the tortoise in about 1.11 seconds.
t_{\text{catch}} \approx 1.11\ \text{seconds}The paradox dissolves mathematically. But it does not disappear philosophically. Zeno’s description of the race is not false in the ordinary sense. Achilles really does pass through the tortoise’s earlier positions. There really are infinitely many possible subdivisions of the race. What Zeno gets wrong is the assumption that infinitely many subdivisions require infinitely much time.
The modern answer depends on the idea of convergence.
The partial sums of a shrinking series approach a limit. For example:
S_n = \sum_{k=1}^{n}\left(\frac{1}{2}\right)^kAs (n) increases, (S_n) gets closer and closer to 1.
\lim_{n\to\infty} S_n = 1This is the heart of the mathematical solution. The sequence has infinitely many steps, but the total distance is finite. The total time is finite too, assuming the motion is continuous, and the speed remains well-behaved.
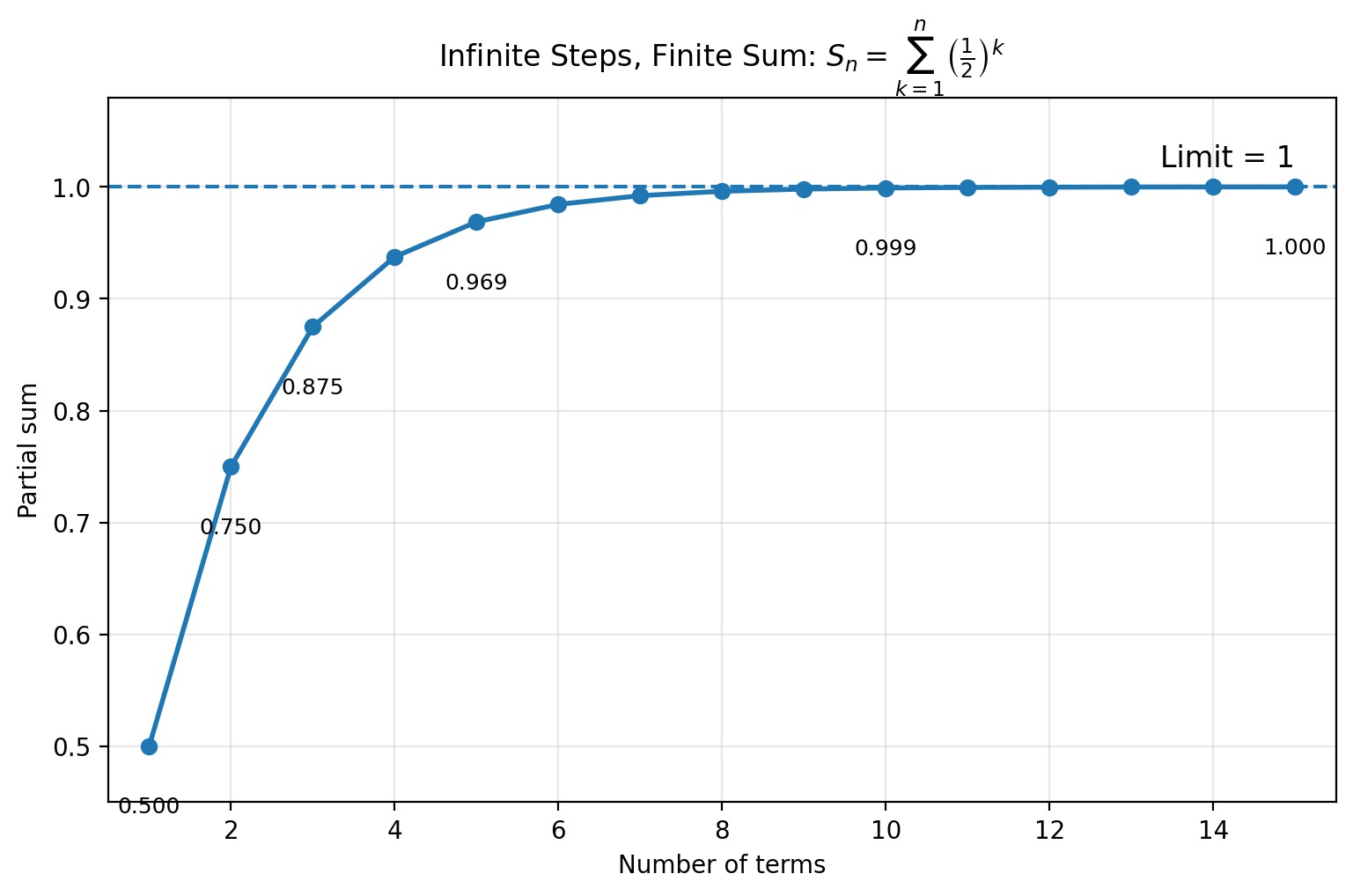
Figure 3. Infinite Steps
The Arrow Paradox
Zeno’s Arrow paradox attacks motion from another direction.
Imagine an arrow flying through the air. At any single instant, the arrow occupies a particular position. At that instant, it is exactly where it is. It is not yet at the next position, nor is it at the previous one.
So, Zeno asks, where is the motion?
If time is made of instants, and if the arrow is motionless at each instant, then how can motion arise from a collection of motionless moments?
This paradox is different from the Dichotomy and Achilles arguments. It is not mainly about an infinite sequence of distances. It is about time itself. If time is composed of indivisible instants, then motion becomes difficult to locate. At a single frozen instant, nothing appears to move.
A photograph captures this problem nicely. A photograph of a moving car does not show motion itself. It shows a car at a position. Motion appears only when we understand the position as part of a sequence.
Modern physics and calculus answer this by treating velocity not as a visible change inside a single instant, but as an instantaneous rate of change.
Average velocity is easy to understand:
v_{\text{avg}} = \frac{\Delta x}{\Delta t}This says that average velocity equals change in position divided by change in time.
Instantaneous velocity is more subtle. It is defined as the limit of average velocity as the time interval becomes arbitrarily small:
v(t) = \lim_{\Delta t\to 0}\frac{x(t+\Delta t)-x(t)}{\Delta t}The arrow does not need to move “inside” a frozen instant. Its motion is represented by the way its position changes over time. Velocity belongs to the structure of the function, not to a single isolated snapshot.
That is a powerful mathematical response. But again, Zeno has forced us to become more precise. He makes us distinguish between position and motion, between an instant and an interval, between a snapshot and a process.
The arrow paradox is not silly. It is a warning about confusing the parts of a description with the whole of reality.
Infinity as the Real Subject
The reason Zeno’s paradoxes endure is that they are not really about turtles, arrows, or people crossing rooms. They are about infinity.
There are at least two kinds of infinity at work here.
First, there is the infinity of division. A line segment can be divided in half, then half again, and so on. There is no obvious stopping point. This suggests that space may be infinitely divisible.
Second, there is the infinity of sequence. Once we begin listing the required steps, the list seems endless. First half the distance. Then half the remainder. Then half again.
Zeno’s genius was to combine these two ideas and turn them against motion.
If every finite act contains infinitely many parts, then how can any finite act be completed?
The modern answer is that infinitely many parts can form a finite whole. That answer now seems familiar because infinite series are part of standard mathematics. But the idea is far from obvious. It is one of the great achievements of mathematical thought.
A simple geometric series shows the point:
a + ar + ar^2 + ar^3 + \cdots = \frac{a}{1-r}provided that:
|r| < 1In the Dichotomy paradox, the first term is:
a = \frac{1}{2}and the common ratio is:
r = \frac{1}{2}So:
\frac{a}{1-r} = \frac{\frac{1}{2}}{1-\frac{1}{2}} \frac{\frac{1}{2}}{\frac{1}{2}} = 1The infinite sum equals the finite distance.
This is why Zeno’s argument fails mathematically. But it fails in a revealing way. It shows that common sense alone is not enough. We needed a theory of limits to explain what everyday experience already knew.
The Difference Between Solving and Dismissing
It is tempting to say that calculus solved Zeno’s paradox and leave it there.
In one sense, that is true. The mathematics of limits gives a clean answer to the problem of infinite subdivision. Achilles catches the tortoise. The walker crosses the room. The arrow moves.
But there is a difference between solving a paradox and dismissing it.
A bad paradox depends on a cheap trick. Once the trick is exposed, nothing remains.
Zeno’s paradox is different. Even after the mathematical answer is given, the original problem remains intellectually productive. It continues to ask useful questions.
What is continuity?
What is an instant?
Is space made of points, or are points abstractions we impose on space?
Is time a flowing reality, or a coordinate in a mathematical model?
Does mathematics describe the world directly, or does it provide a structure that predicts the world?
These are not dead questions. They return in different forms in philosophy, physics, and mathematics. Zeno’s paradox survives because it sits near the boundary between lived experience and formal explanation.
We live in motion. But to explain motion, we must translate it into distance, time, velocity, sequence, and limit. Each translation clarifies something. Each translation also changes the problem.
The Paradox as a Lesson in Explanation
There is a deeper lesson here.
Zeno shows that an explanation can fail even when the reality being explained is obvious.
Motion happens. No serious person doubts that. But saying “motion happens” is not the same as explaining how motion is possible within a particular theory of space and time.
That distinction matters far beyond ancient philosophy.
In science, statistics, and history, we often begin with facts that seem obvious. A species changes. A river cuts a valley. A baseball player declines with age. A market rises or falls. A civilization expands. A population migrates.
But explanation requires structure. We need a model. We need assumptions. We need a way to connect observations to causes.
Zeno’s paradox reminds us that the structure of explanation can become unstable. Sometimes the model makes the obvious seem impossible. When that happens, the answer is not to reject experience immediately. It is to examine the assumptions inside the model.
That may be the real value of the paradox.
Zeno slows us down. He makes us ask what we mean by motion, distance, time, and completion. He takes a simple act and reveals the hidden machinery of thought inside it.
A single step across a room becomes a philosophical event.
Why the Paradox is Still Discussed
Zeno was wrong if his goal was to prove that motion is impossible.
But he was right that motion is stranger than it appears.
The paradox matters because it teaches humility. We should be careful when we assume that ordinary experience is simple. The simplest events often contain the deepest assumptions.
Walking across a room feels immediate. But when analyzed mathematically, it opens into infinity.
A runner passing a tortoise feels obvious. But when divided into successive positions, it becomes a puzzle about convergence.
An arrow flying through the air feels undeniable. But when frozen into instants, it becomes a question about time.
In each case, Zeno forces us to notice that reality and explanation are not identical. Reality happens. Explanation tries to account for how it happens. The gap between the two is where paradox lives.
The modern mathematical answer is beautiful:
\sum_{n=1}^{\infty}\left(\frac{1}{2}\right)^n = 1An infinite process can have a finite limit.
But the philosophical lesson is just as important:
The world may move easily, but our concepts do not always move with it.
Conclusion: The Infinite in the Ordinary
Zeno’s paradox begins with common sense and ends with infinity.
That is why it remains powerful. It does not take us away from ordinary life. It takes ordinary life more seriously than we usually do.
A walk across the room becomes a question about infinite division. A race becomes a question about convergence. An arrow becomes a question about time, instants, and change.
The paradox is not really asking whether motion exists. It is asking whether our account of motion is coherent.
That is a much better question.
Achilles catches the tortoise. The arrow reaches the target. I cross the room.
But after Zeno, none of these things seems quite as simple as they did before.
The world still moves.
The mystery is that we can explain it at all.